
AI 與記憶體技術的融合應用:下一世代運算的關鍵轉折


前言
隨著人工智慧(AI)模型的規模急遽膨脹與應用多元化,對底層硬體資源的要求也達到前所未有的高度。其中,「記憶體」作為連接資料與運算核心的關鍵橋樑,正從傳統儲存角色進化為智慧運算的一環。在 AI 與記憶體技術的融合趨勢下,創新架構、材料與系統設計正快速推進,帶動新一波半導體產業革新。特別是在大型語言模型(LLM)、自駕車、資料中心以及邊緣運算等應用場景下,AI 與記憶體技術的融合已成為不可逆轉的趨勢。
AI 與記憶體融合的動因:來自記憶體牆的壓力
傳統 Von Neumann 架構下,處理器與記憶體分離。AI 模型需要頻繁存取龐大參數與特徵資料,導致資料搬移延遲增加(latency)、功耗大幅上升、記憶體頻寬成為瓶頸。這一現象被稱為「記憶體牆(Memory Wall)」,成為 AI 模型擴展與推論效率提升的最大障礙之一。為突破此限制,研究者與晶片設計廠商開始將「AI 與記憶體」進行更深層次的整合(圖1)。
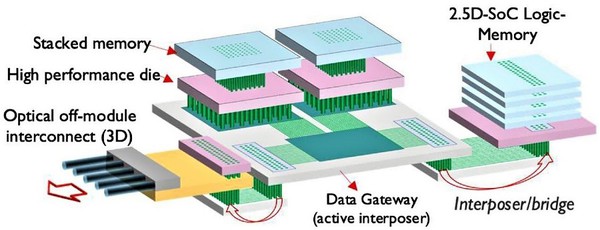 (圖一)
(圖一)
五大融合技術與應用方向
Compute-in-Memory(CIM):記憶體內直接運算
記憶體內運算(Computing-in-Memory, CIM)是一種將運算功能整合到記憶體中的新興技術(圖2)。技術的核心理念是在記憶體中內建計算能力,這種方法不僅減少了資料在處理器和記憶體之間的傳輸時間,還減少了相關的能量消耗和延遲。隨著人工智慧和機器學習應用對計算能力需求的增加,記憶體內運算(CIM)技術正成為解決計算瓶頸的重要途徑。
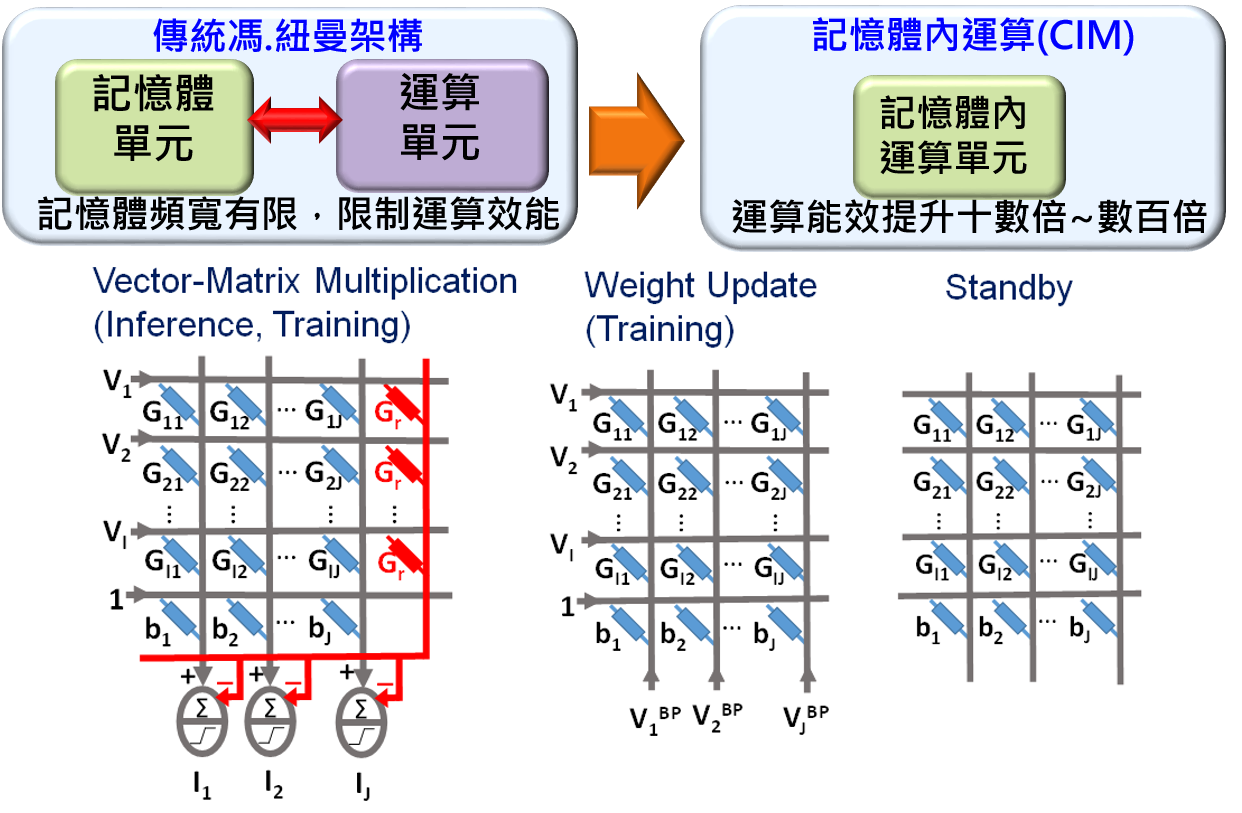 (圖二)
(圖二)
記憶體壓縮與管理最佳化
在 AI 模型推論與訓練過程中,模型參數、Feature Map、權重等需大量記憶體空間。若未經最佳化配置,容易導致記憶體浪費與溢位。
LPDDR5 與 DDR5 解決方案可搭配 AI 框架(如 PyTorch、TensorRT),實現高效的記憶體壓縮與資料重新配置,降低延遲並提升運算速度。
最佳化技術:
- 模型壓縮(Model Compression):透過剪枝(pruning)、量化(quantization)降低模型體積。
- 記憶體重複使用(Memory Reuse):Layer fusion, Memory Pool
- AI 自動調配記憶體:使用RL或ML決策模型做動態分配。
實際應用:
- PyTorch與TensorFlow推出Memory-Aware模型部署工具,NVIDIA TensorRT針對Edge裝置進行記憶體使用壓縮優化。
AI驅動記憶體健康監控與預測維護
AI 技術也能反過來「服務記憶體」,協助SSD、NAND、DRAM等元件預測健康狀態與壽命剩餘。達到監控項目:Bit Error Rate(BER)成長趨勢、P/E Cycle(擦寫次數)過度使用預警、ECC數量增長.資料溫度等等(圖3)。
Micron 的企業級 SSD 產品(如 9400 系列)內建 AI 演算法,可預測 NAND Flash 壽命與健康狀態,並根據寫入模式調整 Wear Leveling 策略,降低故障風險,提升資料中心的可靠性。
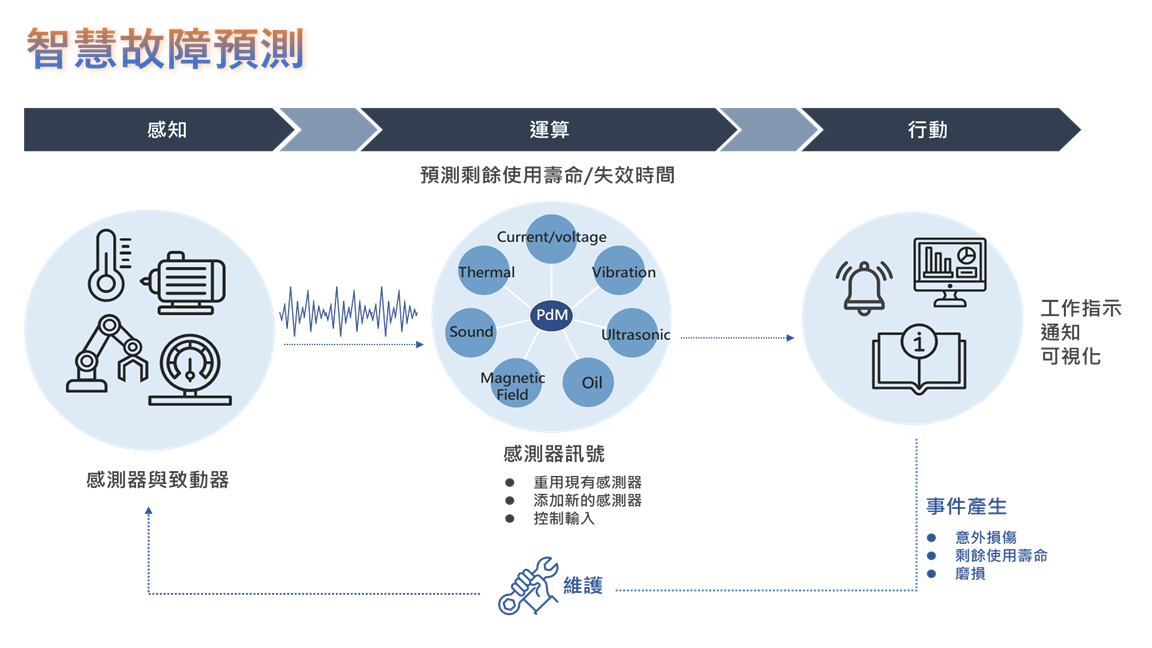 (圖三)
(圖三)
高頻寬記憶體(HBM):針對AI加速的記憶體方案
HBM3是一種用3D堆疊起來的高效能DRAM,透過先進封裝使其密度增加、體積更小、功率消耗更少,來達到更高的頻寬及儲存效果。技術方面將好幾片晶圓堆疊,再透過矽穿孔的技術,像牙籤般將每層的晶圓串住,最後再做封裝(圖4)
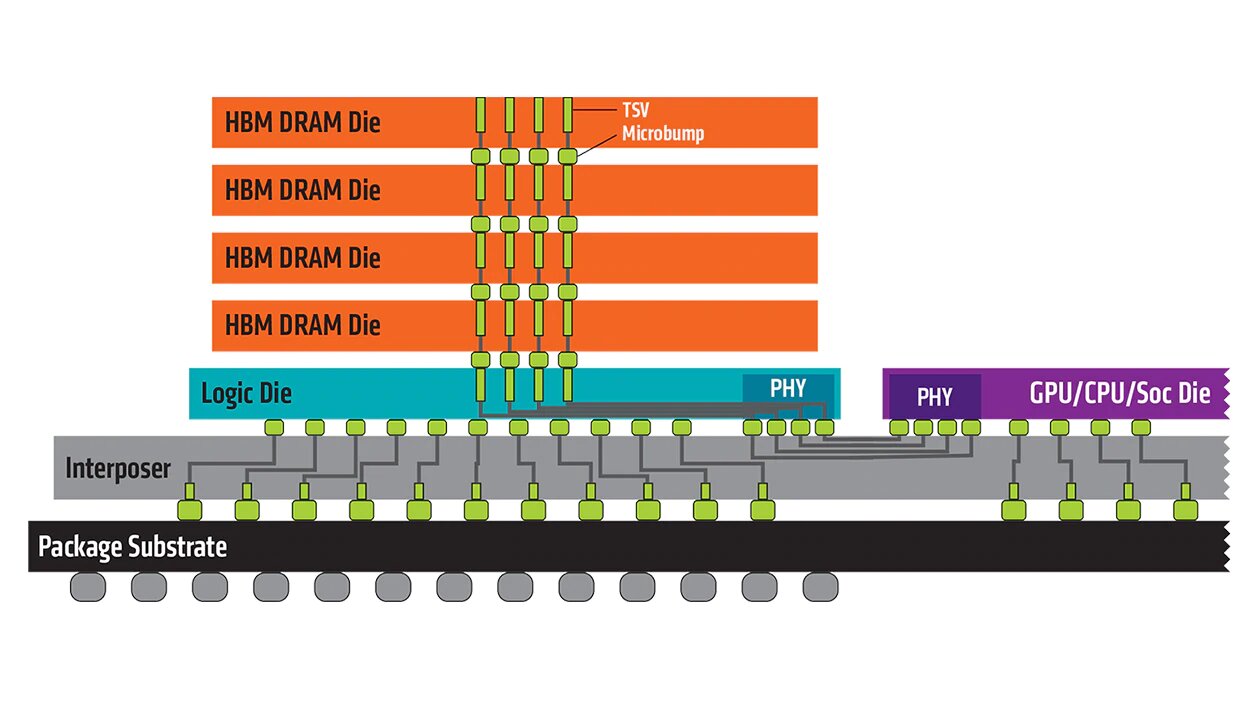 (圖四)
(圖四)
高頻寬記憶體匯流排,在擁有四塊DRAM裸晶的高頻寬記憶體堆上,每顆裸晶各有兩條128位元的通道,加起來共有8條。與其他DRAM,如DDR4、DDR5相比起來更加寬闊。而因記憶體的最大連接數多,高頻寬記憶體就須以更新的方式來連接到處理器,為此而打造矽片(插入器),用以連接記憶體及處理器,以減短記憶體的路徑。從(圖5)及(表1)中,可看出HBM規格上的演進趨勢,及目前在各大原廠針對HBM的市場開發進度。
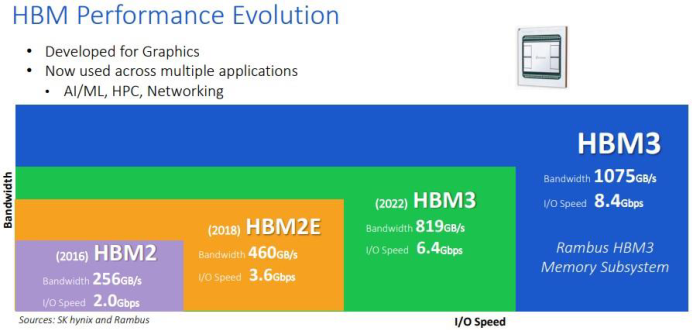 (圖五)
(圖五)
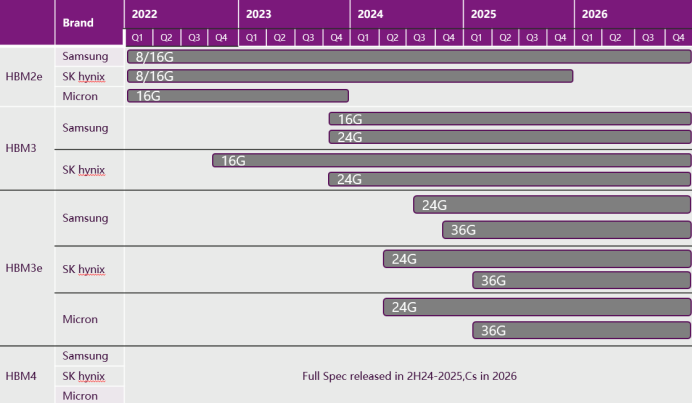 (表一)
(表一)
類腦記憶體架構
運行大型人工智慧演算法產生的高碳排放對環境有害,而隨著算法變得越來越龐大,情況只會變得更糟,但有一種解決方案,稱為類腦神經計算,其使用包含電子模擬電路的超大型集合系統,來模擬神經系統中存在的神經生物學結構。其中一種名為NeuRRAM 的新型神經形態晶片,該晶片包含了 300 萬個儲存單元,和數千個內置在其硬體中以運行演算法的神經元。
此晶片使用了一種相對較新的記憶體類型,稱為電阻式 RAM 或 RRAM。與以前的 RRAM 晶片不同,NeuRRAM 被設計為以「模擬方式」運行,可以節省更多的能源和空間。數位儲存是二進制的( 1 或 0),而 NeuRRAM 晶片中的模擬儲存單元可以在一個完全連續的範圍內儲存多個值。這讓這個晶片可以在相同數量的晶片空間中,儲存更多來自大量 AI 演算法的資訊。
因此,新晶片可以像數位電腦一樣,執行圖像和語音識別等複雜的人工智慧任務。研究員們表示,其能效提高了 1000 倍,而且也為微型晶片在智慧型手錶和手機等,小型的人工智慧設備中運行越來越複雜的算法開闢了可能性。
市場趨勢及未來展望
根據Yole集團預估,2024年全球記憶體市場營收達到創紀錄的1700億美元。其中,DRAM營收貢獻約970億美元,這包含HBM記憶體貢獻約180億美元。至於NAND記憶體營收貢獻約680億美元。
2025年展望,記憶體預計營收將達到2,000億美元,其中DRAM約1,290億美元,這包含HBM貢獻的340億美元。NAND貢獻約650億美元。
簡單來說,隨著AI和HPC的出現,讓HBM記憶體趁勢崛起,全球生成式AI市場及規模成長率大幅提高(圖6),除了2025年HBM營收成長將近一倍之外,預計到2030年營收將達到約980億美元,將佔據一半以上的DRAM營收比例。
HBM 與 CIM 類型記憶體年複合成長率(CAGR)將超過 30%,記憶體與 AI 加速器融合晶片(如 AMD XDNA、Google TPU)將成主流
同時,記憶體廠商(如 Micron、SK hynix、Samsung)皆已佈局 AI 專用記憶體產品,包括 HBM、AI DRAM、AI SSD 韌體等。
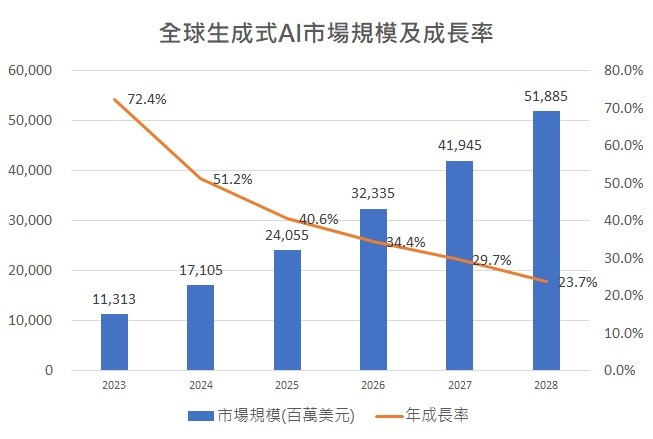 (圖六)
(圖六)
儘管目前無法準確預測2030年生成式AI模型的主流類型與數量,持續推動支援架構的進步與生態系統的建設,將是應對未來變化的核心策略。
記憶體解決方案:從訓練到推理的多元能力
生成式AI模型,如大型語言模型(LLM)、大型視覺模型(LVM)等,對記憶體的需求涵蓋訓練與推理兩大應用場景。訓練過程中需要高頻寬記憶體以處理龐大數據,而推理過程則需要低延遲記憶體以支撐即時決策。
高速記憶體的未來趨勢
- HBM在AI與伺服器系統中的應用
HBM憑藉其層疊設計提供遠高於傳統DRAM的頻寬,但高成本仍是一項挑戰。未來,透過縮小DRAM製程節點並增加層疊數量,HBM的容量將進一步提升,以滿足生成式AI和深度學習對高效能運算的需求。
- 記憶體處理器融合技術的潛力
記憶體處理器(Processor In Memory,PIM)技術將數據處理直接整合至記憶體層,有效消除處理器與記憶體之間的瓶頸,顯著提升AI應用對高頻寬和低延遲的性能需求。
展望未來:記憶體技術的關鍵角色
生成式AI的快速發展對記憶體技術提出全新要求。從先進封裝到處理器記憶體融合,記憶體解決方案將在推動生成式AI技術進步中扮演重要角色。展望未來,到2027年,隨著半導體製程進入2nm以下,智慧型手機等行動裝置預計將更多地採用先進記憶體技術,全方位支撐生成式AI的應用需求。
AI 與記憶體技術的融合,是推動新一代智慧應用與高效能運算的關鍵。隨著模型規模不斷擴大、資料存取需求倍增,單純提升處理器效能已不足以解決「記憶體牆」問題。未來將朝向更高頻寬、更低延遲的記憶體技術發展,並結合計算靠近資料的概念(如 CIM),以減少資料搬移開銷並提升整體能效。
茂綸針對記憶體方面,在代理Micron上的產品組合橫跨DDR4/DDR5、LPDDR4/5、SSD、GDDR,可針對 AI 工作負載提供高頻寬、低延遲與高可靠度的記憶體解決方案。
透過完整的產品線與技術佈局,Micron 能協助客戶在資料中心到邊緣實現完整的 AI 生態系,加速 AI 研發與落地應用,針對不同層級的 AI 工作負載提供最佳解決方案,憑藉這些技術,Micron 協助客戶突破「記憶體牆」,在資料中心與邊緣場景中加速 AI 的落地應用,推動新一代智慧運算的發展。
參考資料
You may also want to know






Links
Follow us on Macnica Galaxy social media




©Copyright 2026 Macnica Galaxy Inc.